
Shadow AI
cuando la IA no autorizada saca información del campus sin que te des cuenta
Usar herramientas de IA “por tu cuenta” puede ahorrar tiempo, pero también puede mover datos fuera del control de la Universidad y complicar privacidad, calidad y cumplimiento.
Introducción
La IA ya está en el día a día: redactar un correo, resumir apuntes, preparar una tutoría, ordenar ideas para una memoria de investigación o aclarar un procedimiento administrativo. Con prisas y mil ventanas abiertas, lo fácil es copiar y pegar un texto “un momento” en una herramienta pública o en un complemento del navegador.
Ahí aparece el shadow AI: uso de IA no autorizada (o no gestionada) para tareas de estudio o trabajo. No suele haber mala intención; suele haber urgencia. El problema es que, sin darnos cuenta, podemos sacar fuera datos personales, información académica, documentos internos o borradores sensibles, y además tomar decisiones con resultados que parecen convincentes pero pueden estar equivocados.
Este artículo aterriza riesgos y decisiones prácticas para PAS, PDI y alumnado, con un objetivo sencillo: aprovechar la IA sin llevarnos por delante la confidencialidad ni la calidad del trabajo.
Qué es shadow AI y por qué afecta tanto fuera y dentro de la Universidad
Shadow AI es cualquier uso de IA en el que una persona emplea herramientas, cuentas o funciones de IA sin que estén aprobadas o gobernadas por la organización (o sin conocer sus condiciones de tratamiento, retención y seguridad). Puede ser un chatbot público, una app móvil, una extensión del navegador, una web para transcribir audio, un “resumidor” de PDFs o una función de IA integrada en un servicio que has activado con tu cuenta personal.
¿Por qué importa? Porque en la práctica se combinan tres cosas:
- Movimiento de datos: lo que pegas o subes puede salir del entorno controlado (y quedarse registrado).
- Decisiones y calidad: la IA puede “rellenar huecos” con seguridad aparente (lo que NIST llama confabulación) y eso se traduce en errores en actas, expedientes, convocatorias o trabajos académicos.
- Superficie de ataque nueva: algunas herramientas y agentes pueden ser manipulados (por ejemplo, mediante prompt injection) y empujar a acciones o respuestas no deseadas.
En lo personal, el impacto puede ser desde una exposición innecesaria de datos hasta un disgusto por suplantación o fraude. En la Universidad, el impacto típico es más silencioso: filtraciones pequeñas pero repetidas, confusión en procesos, y más trabajo “de reparación” después.
Qué suele ver una persona: señales útiles y límites
El shadow AI no suele “avisar” con un cartel. Aun así, hay señales que ayudan a decidir con cabeza:
- Te pide pegar texto o subir un fichero que no publicarías en abierto (actas, listados, incidencias, partes médicos, datos de matrícula, evaluaciones, nóminas, presupuestos, borradores de investigación).
- La herramienta no deja claro dónde se procesa el contenido, cuánto tiempo se guarda o con qué fines se usa.
- Estás usando una cuenta personal (o una app móvil) para una tarea de la Universidad, porque “es lo que tenía a mano”.
- Te propone conectar servicios (correo, calendario, almacenamiento, documentos) o te pide permisos amplios “para funcionar mejor”.
- Funciona como magia con información que no le has dado: a veces es porque tiene acceso a más contexto del que crees (historial, ficheros recientes, pestañas, conectores).
Límite importante: el resultado “suena bien” no significa que sea seguro, correcto o apropiado. Una señal aislada no basta: decide por combinación (tipo de dato + herramienta + permisos + destino).
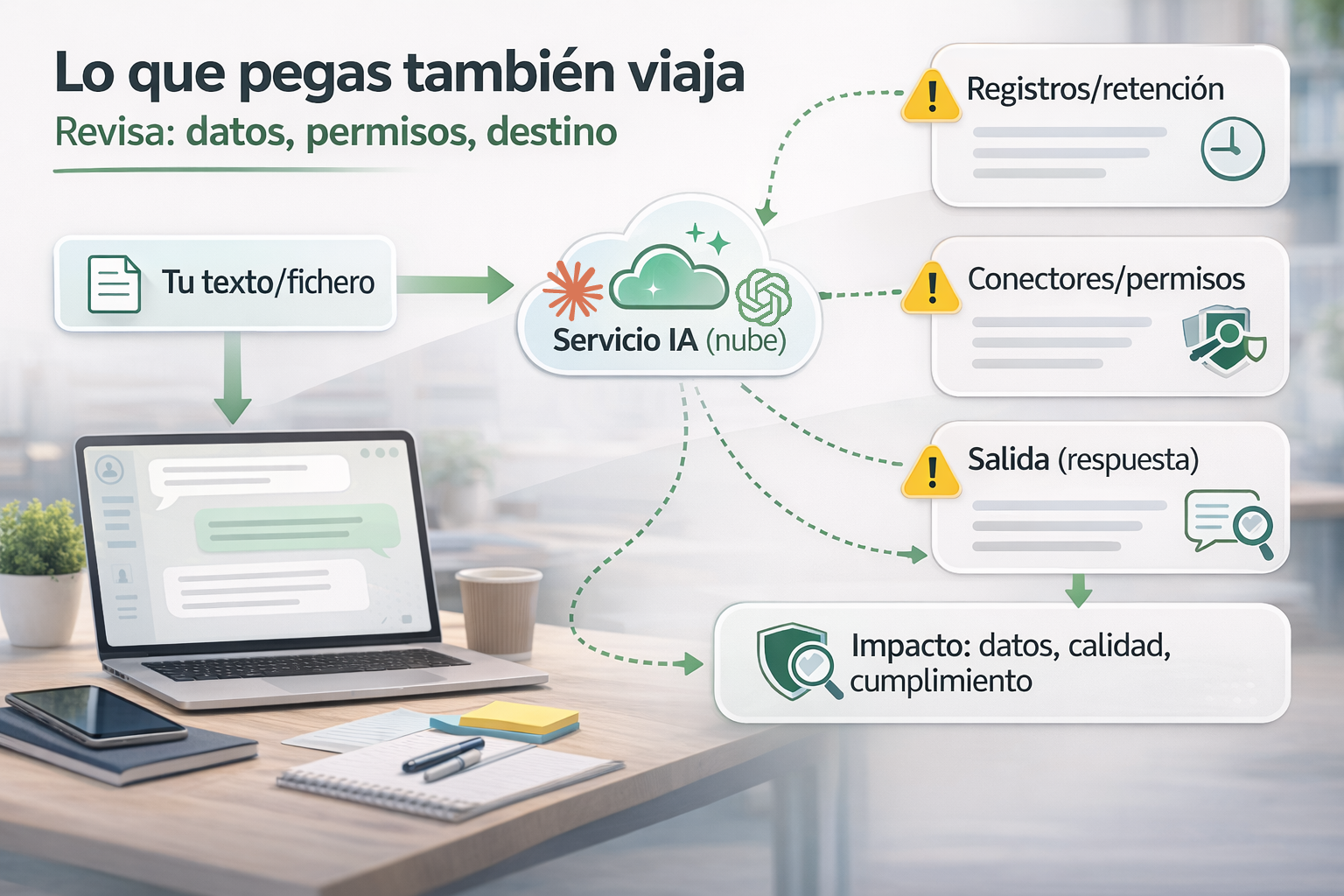
Qué ocurre por dentro (explicado sin jerga)
Para entender el riesgo, ayuda imaginar la IA como un servicio que recibe entradas (texto, ficheros, audio) y devuelve salidas (resúmenes, propuestas, código, tablas). Entre medias hay piezas que no siempre vemos:
- Cuentas y sesiones: si entras con una cuenta personal, tus historiales pueden quedar asociados a ti y a tu dispositivo.
- Retención y registros: incluso cuando un proveedor no “entrena” con tu texto, puede conservarlo un tiempo para operar, seguridad o soporte. Si no está claro, asume que hay retención.
- Permisos y conectores: algunas IAs piden acceso a correo, documentos o almacenamiento para “ser más útiles”. Eso amplía el alcance de lo que la herramienta puede ver.
- Agentes: cada vez más, la IA no solo redacta; también “actúa” (organiza tareas, consulta fuentes, crea borradores, mueve información). Ese salto cambia el riesgo.
- Errores convincentes: la IA puede generar contenido falso con tono seguro (confabulación). NIST lo trata como un riesgo propio de la IA generativa. :contentReference[oaicite:2]{index=2}
- Manipulación de instrucciones: la IA puede ser inducida a comportarse de forma no prevista (por ejemplo, prompt injection directa o indirecta), especialmente si integra contenido externo o documentos. :contentReference[oaicite:3]{index=3}
Riesgo 1: fuga de datos (la “cebolla”)
- Capa 1 (lo que ves): copias un párrafo de un expediente o un acta “solo para resumirlo”.
- Capa 2 (lo que pasa dentro): el texto viaja a un servicio externo; puede quedar en registros/historial y salir del perímetro controlado.
- Capa 3 (cómo ayuda el STIC): orienta sobre qué herramientas están permitidas, qué tipos de datos no deben salir y cómo reducir exposición (clasificación, alternativas, procedimientos).
Riesgo 2: instrucciones maliciosas ocultas (la “cebolla”)
- Capa 1: pegas un documento o sigues un enlace con “material para resumir” y la IA responde raro: pide más permisos, sugiere acciones extrañas o mezcla contenido que no tocaba.
- Capa 2: si la herramienta integra documentos o webs, puede tragarse instrucciones ocultas que alteren su comportamiento (prompt injection indirecta). :contentReference[oaicite:4]{index=4}
- Capa 3: el STIC puede guiar sobre contención, revisión de permisos y reporte temprano para evitar que el problema se extienda.
Riesgo 3: decisiones con base falsa (la “cebolla”)
- Capa 1: aceptas una respuesta “redonda” para una tutoría, una instrucción administrativa o una cita normativa.
- Capa 2: la IA puede confabular: inventa referencias, mezcla fuentes o completa huecos. :contentReference[oaicite:5]{index=5}
- Capa 3: el STIC puede recomendar pautas de verificación y uso responsable para que la IA sea apoyo, no árbitro.
Qué está en juego en la Universidad
En un entorno universitario, la información es variada y a veces se mezcla sin querer: lo académico, lo administrativo y lo personal. Shadow AI convierte “un apaño” en un traslado de datos que puede afectar a:
- Docencia y evaluación: actas, rúbricas, comentarios de corrección, incidencias, adaptaciones, materiales de clase y exámenes. Un pegado accidental puede exponer datos o sesgar decisiones.
- Gestión académica: expedientes, matrículas, becas, movilidad, certificados, comunicaciones con estudiantes. Son datos personales y de especial sensibilidad por contexto.
- Tutorías y orientación: conversaciones, situaciones personales, necesidades de apoyo. Aquí el criterio es claro: si no lo dirías en abierto, no lo pegues en una IA no gestionada.
- Bibliotecas y recursos: búsquedas, listas de lectura, préstamos o consultas pueden revelar intereses o líneas de trabajo si se comparten fuera sin control.
- Investigación financiada y convocatorias: borradores de propuestas, presupuestos, acuerdos, resultados preliminares, propiedad intelectual. Un resumen rápido puede costar caro si sale del circuito adecuado.
Además, hay un coste menos visible: cuando la IA entra “por los laterales”, la Universidad pierde trazabilidad. Y sin trazabilidad es más difícil proteger, cumplir, y también aprender qué funciona.
Cómo ayuda el STIC
El papel del STIC no es “prohibir la IA”, sino ayudar a usarla con criterio: equilibrar productividad con protección.
- Orientación práctica: qué tipos de datos no deben salir a herramientas externas y cómo reducir riesgo en tareas habituales.
- Gobernanza y recomendaciones: pautas de uso aceptable, criterios para herramientas y revisión de permisos, con enfoque realista (bloquear todo suele empujar a atajos). :contentReference[oaicite:6]{index=6}
- Contención y recuperación: si algo se ha compartido de forma inadecuada, acompañamiento para minimizar impacto y activar procedimientos internos.
- Formación y hábitos: decisiones de baja fricción que evitan problemas repetidos.

Lo que ha cambiado en 2025–2026
Dos cambios explican por qué el shadow AI preocupa más ahora que hace un par de años:
- IA “integrada” en herramientas cotidianas: ya no es solo un chatbot en una web. La IA aparece en editores de texto, servicios de transcripción, extensiones, buscadores y asistentes que piden acceso a más contexto.
- De “responder” a “actuar”: los agentes (IA que planifica y ejecuta tareas con cierta autonomía) amplían el impacto de un error de permisos o de una instrucción maliciosa.
En paralelo, se está consolidando el marco regulatorio europeo. El calendario oficial de la UE marca hitos escalonados: el 2 de febrero de 2025 comenzaron a aplicar disposiciones generales (incluida alfabetización en IA) y prohibiciones; el 2 de agosto de 2025 empezaron reglas para IA de propósito general; y el 2 de agosto de 2026 entra en vigor la mayor parte del reglamento, con inicio de la aplicación y la supervisión. :contentReference[oaicite:7]{index=7}
En seguridad, también se ha afinado el lenguaje. Hoy se habla con más claridad de riesgos como prompt injection y de cómo la IA amplía superficie de ataque. NIST lo recoge como riesgo relevante en su perfil para IA generativa. :contentReference[oaicite:8]{index=8}
Datos recientes en contexto
Para situar el fenómeno con cifras recientes (y sin perder de vista que son benchmarks y pueden variar por sector y metodología):
- 78% de personas encuestadas que usan IA en su trabajo admitieron utilizar herramientas no aprobadas por su empleador [WalkMe/SAP, 2025]. :contentReference[oaicite:9]{index=9}
- 4,44 millones USD fue el coste medio global estimado de una brecha de datos en el informe 2025 [IBM/Ponemon, 2025]. :contentReference[oaicite:10]{index=10}
- 63% de organizaciones dijeron no tener políticas de gobernanza de IA para gestionar el riesgo o detectar shadow AI [IBM/Ponemon, 2025]. :contentReference[oaicite:11]{index=11}
- 24% de líderes afirmaron que su organización ya ha desplegado IA de forma generalizada, mientras 12% seguían en fase piloto [Microsoft, 2025]. :contentReference[oaicite:12]{index=12}
- ENISA analizó 4.875 incidentes entre el 1 de julio de 2024 y el 30 de junio de 2025 en su panorama de amenazas [ENISA, 2025]. :contentReference[oaicite:13]{index=13}
Checklist en 30 segundos
- Piensa “tipo de dato” antes que “tarea”: si hay datos personales, expedientes, actas o información interna, evita herramientas no gestionadas; reduces exposición sin complicarte.
- Usa la opción aprobada cuando exista: el camino fácil y seguro debe ser el primero; evita el “atajo” que luego se paga en tiempo.
- No pegues textos completos: si necesitas ayuda, anonimiza y resume tú primero (sin nombres, DNI, matrículas, teléfonos); minimizas daño si te equivocas.
- No subas ficheros por inercia: subir un PDF o una hoja de cálculo suele llevar más contexto del necesario; mejor extraer lo mínimo.
- Revisa permisos como si fueran llaves: si una IA pide acceso a correo, calendario o almacenamiento, para y valora; ese acceso amplía el riesgo.
- Separa cuentas personal y de la Universidad: evita mezclar historiales y documentos; reduce fugas por sincronización y despistes.
- No uses IA para “validar” decisiones sensibles: úsala para redactar o estructurar, y valida siempre con fuentes y criterio humano; evitas confabulaciones.
- Desconfía de resultados demasiado específicos sin referencia: si la IA “cita” normas, fechas o artículos, compruébalo; reduce errores en gestión y docencia.
- Evita extensiones desconocidas del navegador: son cómodas, pero a veces leen páginas y formularios; mejor reducir superficie de riesgo.
- Si dudas, pide ayuda antes: 2 minutos consultando evitan horas de contención después; también mejora la cultura de uso responsable.
Qué hacer si ya ha pasado (sin tecnicismos)
Si ya has pegado o subido información a una IA que no debías, lo útil es actuar rápido y sin intentar “arreglarlo a solas”.
- Para y no sigas compartiendo: cierra la tarea y evita añadir más contexto (a veces el impulso es “aclararlo”, y se empeora).
- Anota lo básico: qué herramienta era, qué tipo de información se compartió (sin repetirla), cuándo ocurrió y desde qué dispositivo; ayuda a evaluar impacto.
- Revisa si diste permisos: si conectaste correo, almacenamiento o cuentas, apunta qué autorizaciones aceptaste; es información clave para contener.
- No lo conviertas en un secreto: avisar pronto suele reducir consecuencias; además permite corregir hábitos y evitar repeticiones.
Canal de ayuda/reporte: Jira / Contactar con su referente local del CAU

Privacidad y trato respetuoso
El shadow AI se combate mejor con hábitos y herramientas útiles, no con culpa. En una universidad conviven perfiles y necesidades distintas: quien atiende ventanilla, quien prepara una clase, quien corrige prácticas, quien escribe un proyecto o quien estudia con presión de entregas.
Por eso el enfoque debe ser proporcional: proteger datos personales y documentos internos, mantener la calidad del trabajo y aprender de los incidentes sin señalar. Reportar a tiempo y compartir dudas ayuda a toda la comunidad, y permite que las medidas sean más ajustadas y menos molestas.
Para terminar
La IA puede ser una buena compañera de trabajo y estudio si se usa con límites claros. El shadow AI aparece cuando la herramienta es rápida, pero el dato que le damos no debería salir del entorno controlado, o cuando delegamos en la IA decisiones que requieren verificación.
Quédate con tres ideas: minimiza el dato, revisa permisos y destino, y valida lo importante. Y si algo se tuerce, no lo tapes: el mejor momento para avisar es pronto.
Una buena decisión a tiempo evita muchos arreglos después.


